BNDF User Guide
Introduction
BNDF is a library for storing and processing large-scale neural data included, but not limited to single(multi) unit and multichannel array recording data in a distributed manner. BNDF's ecosystem is build on top of Apache Spark and Apache Hadoop. For storing large-scale raw data, Apache Parquet a columnar data structure and Apache Hive are used on top of Hadoop distributed file system (HDFS). Meta-data information of raw data, are constructed as nested JSON files and stored in mongoDB. BNDF's APIs can be used in Scala, Java, Python, R and partially in Matlab.
BNDF Ecosystem
The ecosystem of the BNDF and it's open source requirement described in the following diagram.
ARCHITECTURE
BNDF library designed with focus on optimising neural data analysis from two point of view Data Storing and Data Processing.
Input data
Currently, BNDF supports MAT files as raw input data with conditions described in MAT File Library. The structure of the input MAT files can be shown in the diagram below.
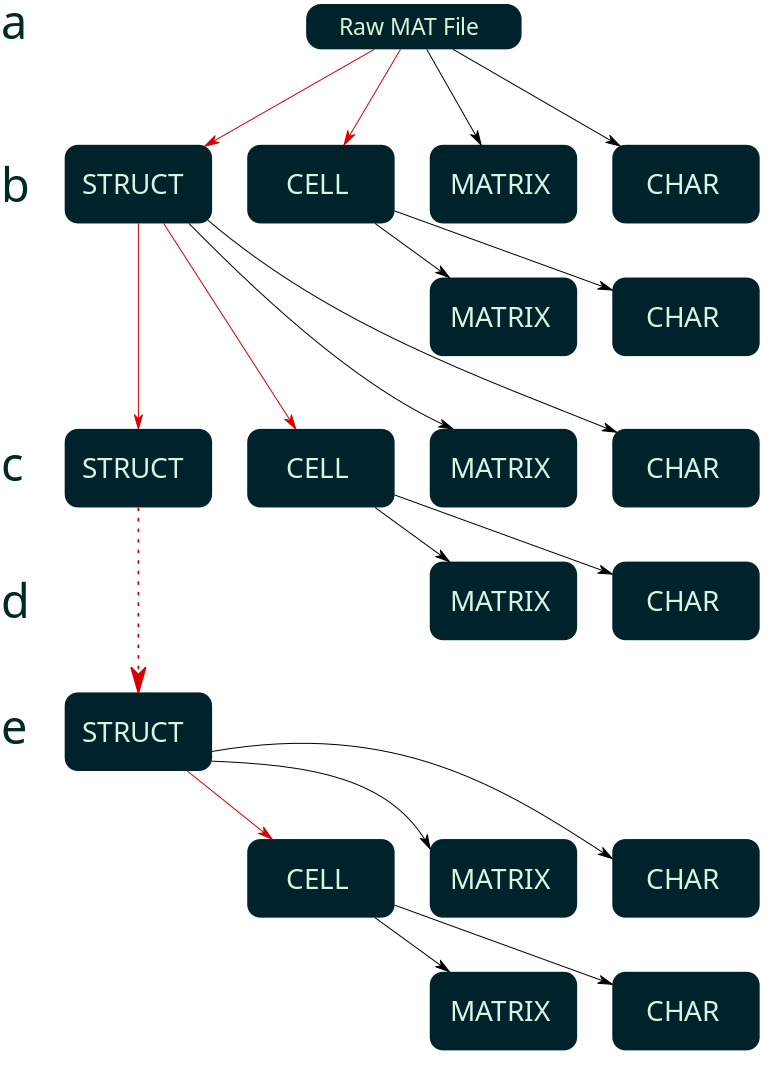
Where in the diagram:
- Raw MAT file consist of struct, cell, matrix and char type in root level of the file.
- Each fields in file could have one of the illustrated structures, while struct and cell type could be nested through next level.
- One-level Struct type nesting, it could be nested through itself or the other types.
- Struct field is capable of n-level nesting.
- The last state of nesting struct field, resulting one of the char or matrix field being the leaf node.
Data Storing
From Data Storing point of view BNDF construct both scalable and standardize formats for meta-data and large scale raw data. The detail structure of the stored data could be found in the diagram below.
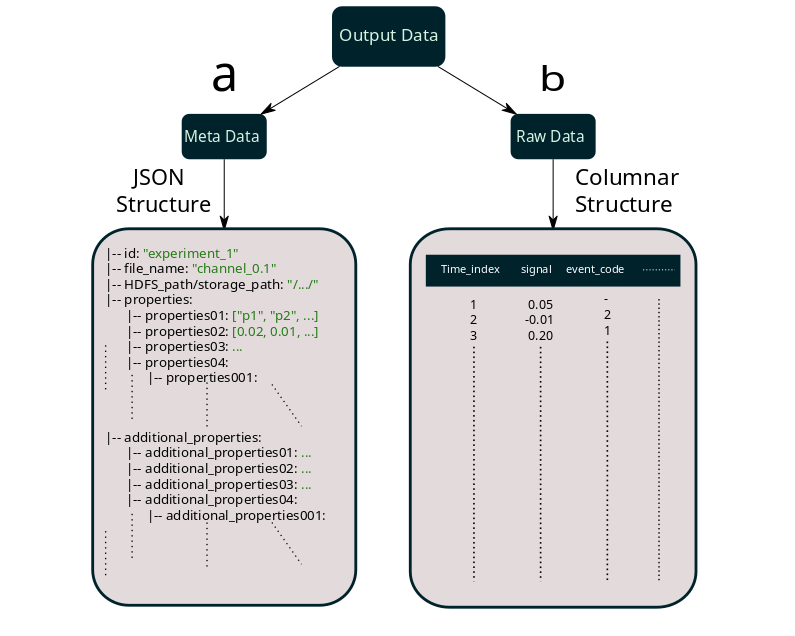
Where in the diagram:
- Nested JSON structure which stored in **mongoDB**. Fields such as `id`, `file_name`, `HDFS_path` and `properties` are necessary while others are optional and could vary for different experiments.
- Horizontally scalable columnar structure which stored as **Parquet** format in HDFS. It could contains more optional columns .
Data Processing
Spark Rich APIS made BNDF flexible in Data Processing with Scala, Java, Python and R. Even one could use partially Matlab. BNDF also could be used with third party libraries such as Thunder through spark's Python API.
Spike Sorting
BNDF provides Spike sorter module as one of the most widely used pre-processing procedures in neural data analysis.

INSTALLATION
Building BNDF from Source
You will need to have Apache Maven 3.6.0 or later installed in order to compile BNDF.
$ git clone https://gitlab.com/neuroscience-lab/bndf
$ cd bndf
$ mvn install
BNDF could run on any cluster or single machine running and configured following open source tools
- Apache Hadoop
- Apache Spark
- Apache Hive
- Apache Zeppelin (Optional)
- mongoDB
Currently, BNDF have two modules RecordingDataLoader and Spike sorter.
RecordingDataLoader
RecordingDataLoader executive jar-file take two parameters in the following order
- DATA_PATH
- MONGO_URI
$ spark-submit \
--class com.ipm.nslab.bndf.RecordingDataLoader \
--master SPARK_MASTER(s)_URL | yarn | mesos \
--deploy-mode client | cluster \
--executor-memory ${SPARK_EXECUTOR_MEMORY}G \
--total-executor-cores ${SPARK_EXECUTOR_CORES} \
--driver-memory ${SPARK_DRIVER_MEMORY}G \
PATH_TO_BNDF_JAR_FILE/bndf-${BNDF_CURRENT_VERSION}.jar DATA_PATH MONGO_URI
Spike sorter
Spike sorter executive jar-file take two parameters in the following order
- MONGO_URI
- EXPERIMENT_NAME
$ spark-submit \
--class com.ipm.nslab.bndf.Sorter \
--master SPARK_MASTER(s)_URL | yarn | mesos \
--deploy-mode client | cluster \
--executor-memory ${SPARK_EXECUTOR_MEMORY}G \
--total-executor-cores ${SPARK_EXECUTOR_CORES} \
--driver-memory ${SPARK_DRIVER_MEMORY}G \
PATH_TO_BNDF_JAR_FILE/bndf-${BNDF_CURRENT_VERSION}.jar MONGO_URI EXPERIMENT_NAME
Spark-submit's parameters detailed information are available in submitting-applications. For creating a private cluster, running BNDF and detail about its modules configurations see BdnsCluster.
BENCHMARKING
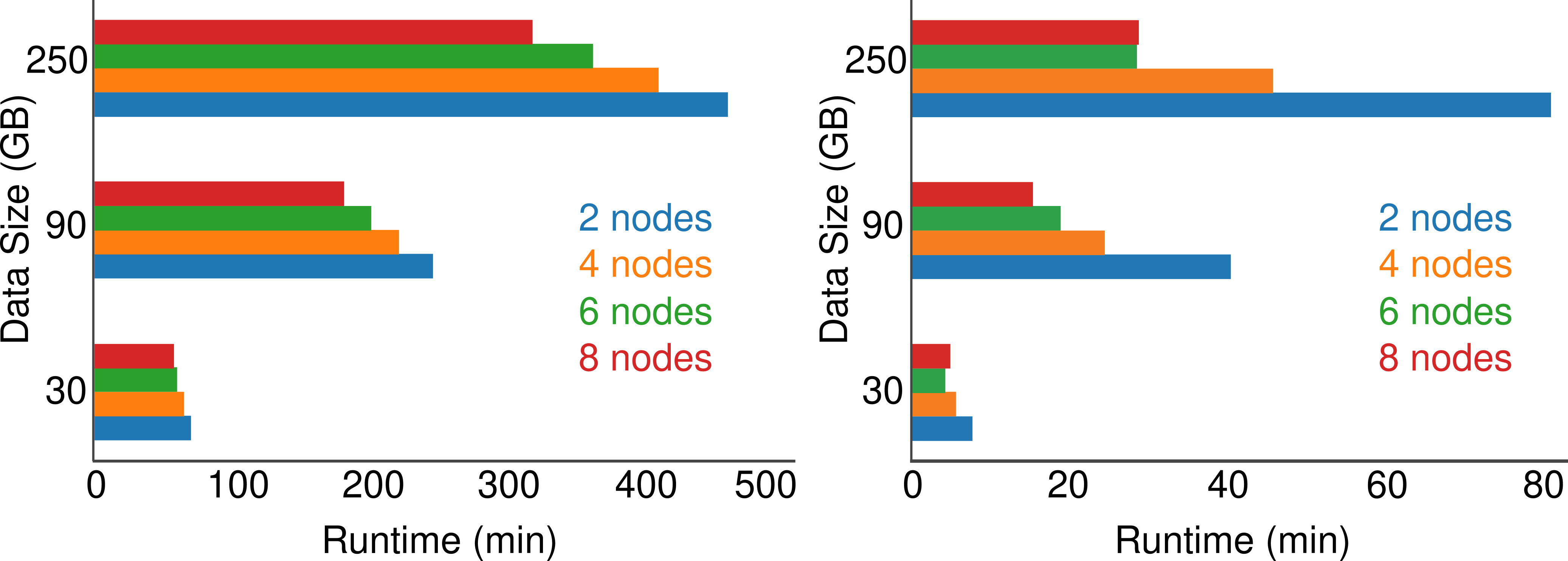
We evaluated BNDF performance benchmarks on three datasets with 30, 90 and 250 GB size.
RecordingDataLoader (I/O)
Left-hand side of the figure corresponds to reading local MAT files and convert them in BNDF standard structure (RecordingDataLoader). The other side related to I/O operations in BNDF structure.
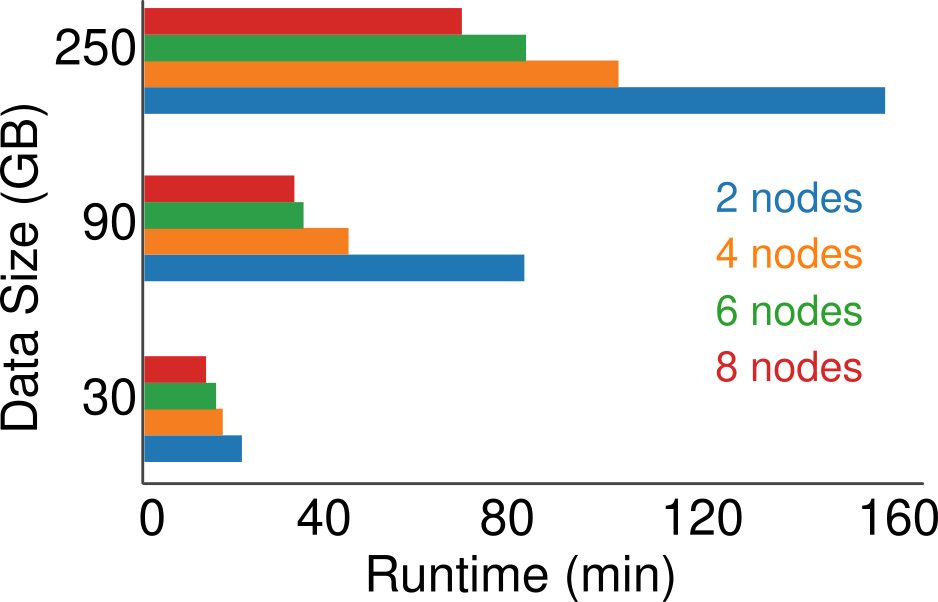
Spike sorter
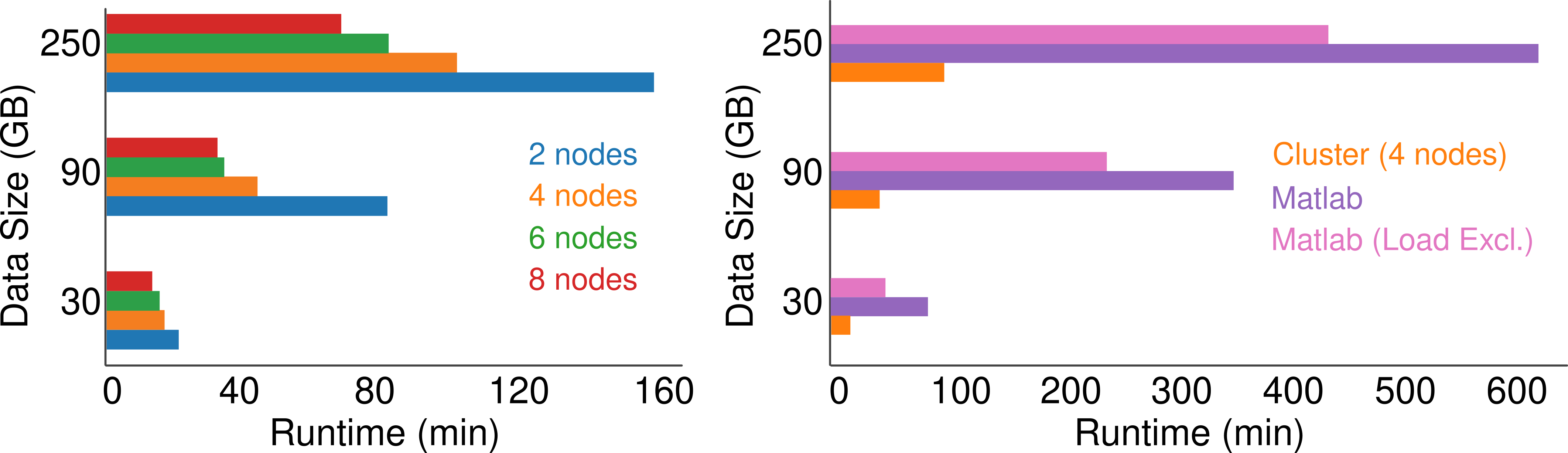
BNDF sorter vs Matlab sorter
DEPLOYING BNDF
Deploying BNDF on a Private Cluster
Instruction for deploying BNDF on private cluster using Docker is fully described at BndfCluster.
BNDF'S APIS
Scala
For analyzing structured data we could use either Spark's shell or Apache Zeppelin. For communicating with mongoDB and hive required dependencies should include in spark-sumbit (see conf). These examples are using sample-data available in sample-data.
Define MongoReader
import com.mongodb.spark.MongoSpark
import com.mongodb.spark.config._
import org.apache.spark.sql.{DataFrame, Dataset, Row, SaveMode, SparkSession}
val MONGO_DB_NAME = "MetaDataDB"
val MONGO_URI = s"${MONGO_URI}"
val MONGO_COLLECTION = "Experiments"
def Reader(spark: SparkSession, uri: String, database: String, collection: String) :DataFrame = {
val readConfig = ReadConfig(Map("uri" -> uri, "database" -> database, "collection" -> collection))
MongoSpark.load(spark, readConfig)
}
MONGO_URI is the mongoDB URL defined in the cluster setup. if you used BndfCluster
for deploying BNDF, change this to:
val MONGO_URI = "mongodb://root:ns123@mongos:27017/admin"
Check Existing Experiments
val experimentMetaData = Reader(spark, MONGO_URI, MONGO_DB_NAME, MONGO_COLLECTION)
// Spark Shell
experimentMetaData.show(50)
// Zeppelin
z.show(experimentMetaData.limit(50))
Output:
+----------------------------------+-----------------------------------------------+-----------+
|_id |fullPath |parentPath |
+----------------------------------+-----------------------------------------------+-----------+
|Experiment_Kopo_2018-04-25_J9_8600|/sample-data/Experiment_Kopo_2018-04-25_J9_8600|sample-data|
|Experiment_Kopo_2018-04-25_J9_8900|/sample-data/Experiment_Kopo_2018-04-25_J9_8900|sample-data|
+----------------------------------+-----------------------------------------------+-----------+
Read Experiment_Kopo_2018-04-25_J9_8600 Directly from HDFS
Check meta-data
- Read Schema
val metaData = Reader(spark, MONGO_URI, MONGO_DB_NAME, "Experiment_Kopo_2018-04-25_J9_8600")
metaData.printSchema
Output:
root
|-- HDFS_PATH: string (nullable = true)
|-- IS_EVENT: boolean (nullable = true)
|-- Root: struct (nullable = true)
| |-- Property: struct (nullable = true)
| | |-- ADCRange: string (nullable = true)
| | |-- Root: string (nullable = true)
| | |-- SamplingRate: string (nullable = true)
| |-- Root: string (nullable = true)
| |-- Total_Samples: string (nullable = true)
|-- _id: string (nullable = true)
|-- channelik0: struct (nullable = true)
| |-- Property: struct (nullable = true)
. .
. .
. .
- Read Data
metaData.select($"HDFS_PATH", $"IS_EVENT", $"Root", $"_id").show(1, false)
Output:
+------------------------------------------------------------------------+--------+------------------------------+---------+
|HDFS_PATH |IS_EVENT|Root |_id |
+------------------------------------------------------------------------+--------+------------------------------+---------+
|/sample-data/Experiment_Kopo_2018-04-25_J9_8600/events/eventik_1.parquet|true |[[10.0, '10', 40000.0], , 0.0]|eventik_1|
+------------------------------------------------------------------------+--------+------------------------------+---------+
Check events data
- Read All events
val metaDf = metaData.select($"_id", $"HDFS_PATH").filter($"IS_EVENT".isNotNull)
val namespathsMap = metaDf.collect.map(x => Array(x.getAs("_id").toString, x.getAs("HDFS_PATH").toString))
val eventsDataSet = namespathsMap.map(x => {
spark
.read
.parquet(x.apply(1))
.withColumn("eventsName", lit(x.apply(0)))
}).reduce((df1, df2) => df1.union(df2)).persist
- Read Schema
eventsDataSet.printSchema
Output:
root
|-- EventTime: long (nullable = true)
|-- EventCode: long (nullable = true)
|-- SamplingRate: double (nullable = true)
|-- eventsName: string (nullable = false)
- Read Data
eventsDataSet.orderBy($"EventTime").show(5)
Output:
+---------+---------+------------+----------+
|EventTime|EventCode|SamplingRate|eventsName|
+---------+---------+------------+----------+
| -1532000| 0| 40000.0| eventik_1|
| -1| 1| 40000.0| eventik_1|
| 1634585| 0| 40000.0| eventik_1|
| 1673707| 9| 40000.0| eventik_1|
| 1675086| 128| 40000.0| eventik_1|
+---------+---------+------------+----------+
We can get summary of channel data with the same approach.
Read Experiment_Kopo_2018-04-25_J9_8600 from HIVE
Reading data from Hive has two key advantages
- It is faster to read
- All channel and events data are stored in long table
- It provide optimized sql queries
Show Existing Hive Databases
spark.sql("SHOW DATABASES").show()
Output:
+------------+
|databaseName|
+------------+
| default|
| rawdatadb|
+------------+
Using rawdatadb database and listing tables
spark.sql("USE rawdatadb")
spark.sql("SHOW TABLES").show()
Output:
+---------+----------------------------------+-----------+
|database |tableName |isTemporary|
+---------+----------------------------------+-----------+
|rawdatadb|experiment_kopo_2018_04_25_j9_8600|false |
|rawdatadb|experiment_kopo_2018_04_25_j9_8900|false |
+---------+----------------------------------+-----------+
Show data
SELECT * FROM experiment_kopo_2018_04_25_j9_8600 LIMIT 5
| Signal | Time | ChannelName |
|---|---|---|
| 1.3995862007141113 | 40004241 | channelik5_1 |
| 1.3884074687957764 | 40004245 | channelik5_1 |
| 1.3884074687957764 | 40004244 | channelik5_1 |
| 1.363419771194458 | 40004242 | channelik5_1 |
Other API's
Currently BNDF is only supported through Scala API, and more specificly with spark-shell or spark-submit jobs. BNDF-cli or python API could be added in the future release.